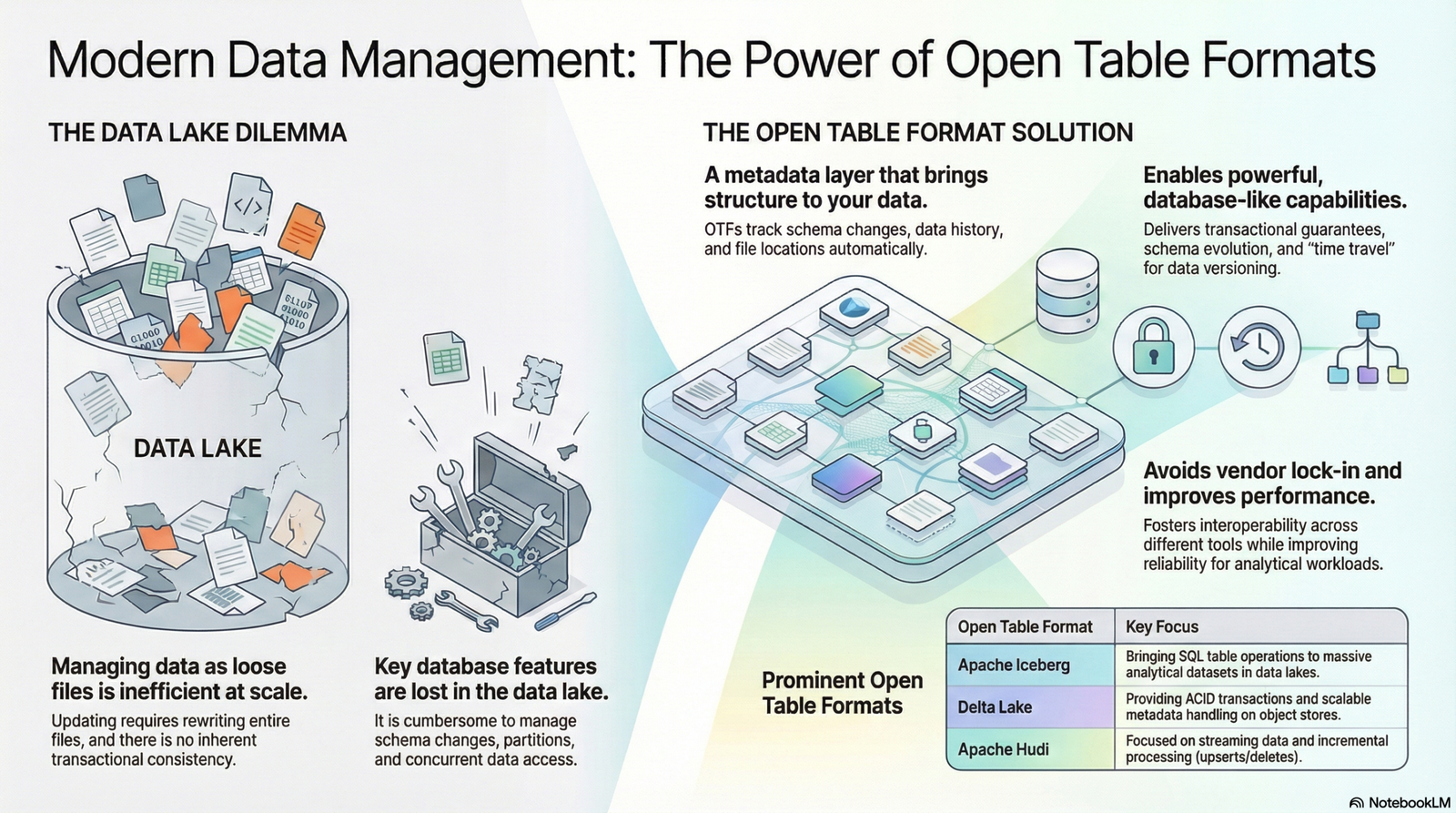
Introduction
DeltaLake is a powerful open-source storage layer that brings reliability and performance to data lakes. It provides ACID transactions, schema enforcement, and time travel capabilities, making it ideal for building scalable and reliable data pipelines.
Getting Started with AWS Glue
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load data for analytics. It provides a serverless environment for running ETL jobs and supports various data sources and destinations.
Writing to DeltaLake Format Table
To write data into a DeltaLake format table in AWS Glue, follow these steps:
- Create a GlueContext object to connect to your data source and destination.
- Read the source data using the GlueContext and convert it into a DynamicFrame.
- Apply any transformations or filters to the DynamicFrame as needed.
- Write the transformed data to the DeltaLake format table using the `glueContext.write_dynamic_frame.from_options` method.
- Specify the format options for writing to DeltaLake, such as the table name, file format, and partitioning options.
- Run the AWS Glue job to execute the data write operation.
Example Code
from awsglue.context import GlueContext
from pyspark.context import SparkContext
sc = SparkContext()
glueContext = GlueContext(sc)
# Read the source data
source_dyf = glueContext.create_dynamic_frame.from_catalog(database='my_database', table_name='my_source_table')
# Apply transformations
transformed_dyf = apply_transformations(source_dyf)
# Write to DeltaLake format table
glueContext.write_dynamic_frame.from_options(
frame=transformed_dyf,
connection_type='s3',
connection_options={'path': 's3://my_bucket/my_table'},
format='delta'
)
Conclusion
Writing data into DeltaLake format tables in AWS Glue jobs is straightforward and allows you to take advantage of the reliability and performance benefits offered by DeltaLake. By following the steps outlined in this blog post and using the example code provided, you can easily incorporate DeltaLake into your data pipelines and ensure the integrity and scalability of your data lake.